인덱스는 데이터베이스 테이블에 대한 검색 성능의 속도를 높여주는 자료구조다. 특정 컬럼에 인덱스를 생성하면, 해당 컬럼의 데이터들을 정렬해 별도의 메모리 공간에 데이터의 물리적 주소와 함께 저장된다.
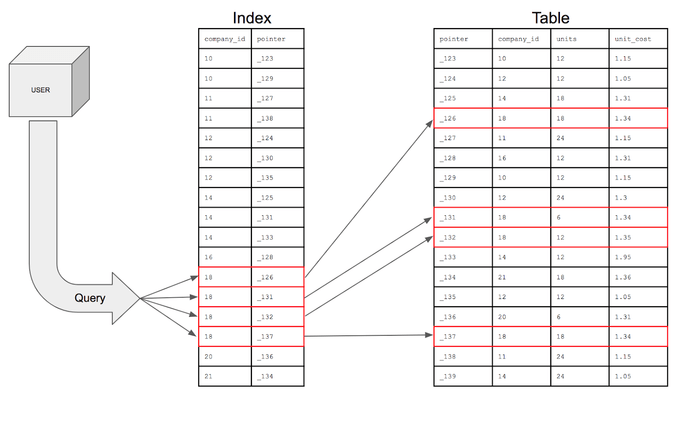
[인덱스를 활용한 조회 과정]
1. Company라는 가상의 테이블 안에 company_id란 컬럼이 인덱스로 설정됐다고 가정하자. 사용자가 Where 조건으로 company_id = 18이란 쿼리를 실행하면 데이터베이스는 별도의 인덱스로 만들어진 company_id를 먼저 검색한다.
2. company_id란 인덱스(컬럼)는 기본적으로 정렬된 상태로 저장돼 있기 때문에 효율적으로 데이터를 찾을 수 있다. company_id = 18에 해당하는 모든 포인터 값을 찾는다(_126, _131, _132, _137).
3. 인덱스에서 찾은 포인터를 사용해 실제 테이블의 행에 빠르게 접근한다. 테이블의 각 포인터 위치에서 해당되는 데이터를 가져온다.
4. 결과적으로 company_id = 18에 해당하는 모든 행들을 테이블에서 가져온다.
*pointer는 테이블에서 데이터가 저장된 위치를 나타내는 참조값이다.
인덱스는 '정렬'이 기본 상태이므로 특정 조건에 맞는 데이터를 빠르게 찾을 수 있다. 만약 인덱스를 사용하지 않으면 쿼리는 테이블의 모든 행을 순차적으로 읽으면서 조건을 일일이 확인해야 하고 이를 Full Scan이라 한다. 만약 company_id = 18을 찾는다면 모든 company_id 값을 하나씩 비교해야 한다. 이럴 경우 데이터 양이 많을수록 검색 속도는 현저히 느려진다.
실제 테이블에서 인덱스를 확인해보자.
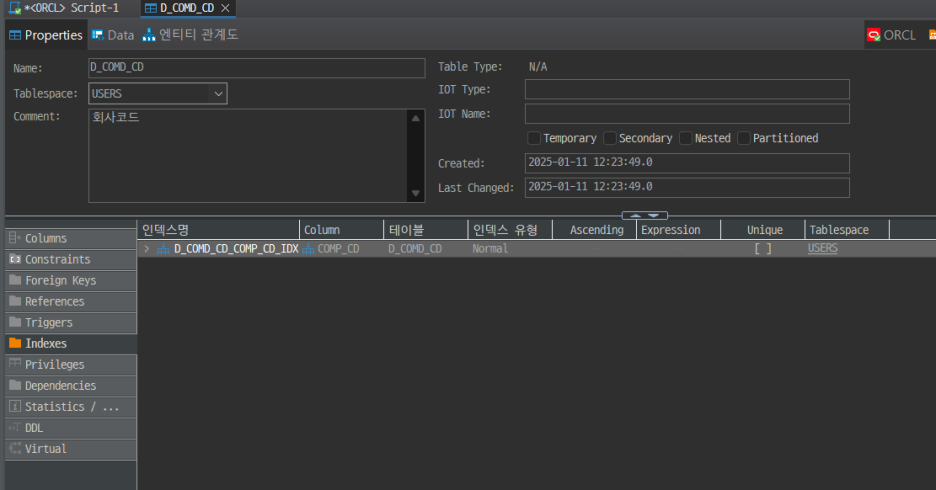
D_COMD_CD 테이블의 정보를 보면 COMP_CD라는 컬럼이 인덱스를 가지고 있다는 사실을 확인할 수 있다. 인덱스 유형의 NORMAL은 가장 일반적인 유형인 B-TREE 구조를 의미한다. B-TREE에 대한 상세 구조는 추후 자세히 알아보자.
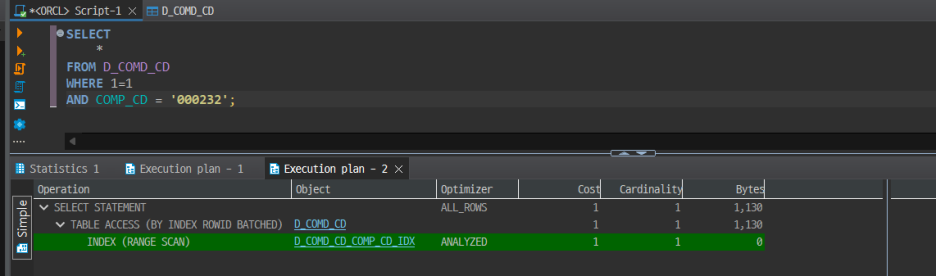
COMD_CD = '000232'란 조회를 시도하자. 위와 같은 구문으로 퀴리의 실행계획을 보면 인덱스인 COMD_CD로 RANGE SCAN을 한다는 계획임을 확인할 수 있다.
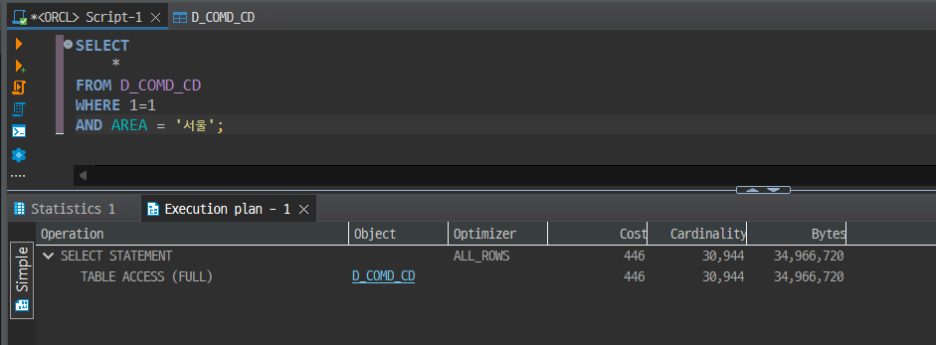
만약 인덱스를 사용하지 않는 조회를 시도하면? AREA = '서울' 조건으로 조회할 때 FULL로 테이블에 접근한다는 계획이다. 테이블에서 모든 행에 접근해 AREA가 '서울'인지 Full Scan해 확인한다는 뜻이다. 이렇게 인덱스를 활용하면 조회에 있어서 속도 향상과 전반적인 시스템 부하를 줄일 수 있다는 이점을 챙길 수 있다.
[인덱스의 단점]
1) 인덱스는 테이블 데이터 외에 별도의 구조로 저장되므로, 테이블 크기가 클수록 인덱스가 차지하는 공간도 커진다. 인덱스를 관리하기 위해서 테이블의 약 10%에 해당하는 별도의 저장 공간이 필요하다. 따라서 테이블에 여러 개의 인덱스를 생성하면 저장 공간이 급격히 증가하기 때문에 인덱스는 최소한으로 생성하는 게 좋다.
2) INSERT, UPDATE, DELETE 처럼 데이터 변경이 잦은 작업에서 성능이 저하된다. 이는 인덱스가 변경된 테이블 데이터 맞춰 추가적인 작업을 수행해야 하기 때문이다. 인덱스는 항상 정렬 상태를 유지해야 하고 테이블 참조를 지속적으로 관리해야 한다는 점을 상기할 경우 이해하기 쉽다.
INSERT나 UPDATE, DELETE는 값이 변경되는 작업이다. 값의 새로운 배치에 따라 인덱스에도 동일한 변화를 줘야 한다. 그 과정에서 노드 분할이나 노드 병합, 트리 재조정이 필요하다. 이 같은 B-TREE 인덱스의 관리 작업은 정렬 상태와 성능을 유지하는 데 필수이며, 소요되는 시간과 비용이 적지 않다. 따라서 값이 자주 변경되는 테이블에 인덱스를 사용하는 건 오히려 비효율적이다.
그렇다면 어떤 상황에서 인덱스를 사용해야 할까
인덱스는 값의 변경이 적고, 찾고자 하는 정보가 적을 때(통상 5%) 활용하면 효율적이다. 만약 찾고자 하는 레코드의 건수가 전체 테이블 레코드의 10 - 15%를 넘어서면 인덱스를 이용하지 않는 게 더 좋다. 인덱스는 어디까지나 두 번에 걸치는 작업이기 때문에 찾고자 하는 레코드가 많을 경우 차라리 Full Scan이 낫다.
[인덱스 생성 전략]

인덱스로 생성할 컬럼을 정할 땐 조건절에 자주 등장하는 컬럼이여야 한다. 동시에 조인 조건 혹은 ORDER BY 절에서 자주 사용되거나 중복되는 데이터가 최소한인(Cardinality가 높은) 컬럼이 좋다. 예로 사원번호처럼 고유의 식별 번호가 있어 중복도가 낮은 게 활용성이 높으며, 성별처럼 남/녀로 구분돼 중복이 많은 건 인덱스 활용성이 나쁘다.
테이블에 중복도가 낮은 컬럼이 없다면 두 개 이상의 컬럼의 합쳐 결합 인덱스를 만드는 것도 좋은 접근법이다. 결합 인덱스로 사용할 컬럼을 선택할 땐 다른 테이블과 조인의 연결고리로 자주 사용되는 컬럼이거나 ORDER BY에서 자주 사용되는 컬럼이어야 한다.
'데이터베이스' 카테고리의 다른 글
| [MYSQL] 옵티마이저와 실행 계획 (0) | 2025.04.04 |
|---|---|
| 인덱스(index)의 종류와 활용 (0) | 2025.03.31 |
| [ORCL] 데이터베이스 아키텍쳐(프로세스) (0) | 2025.03.26 |
| [ORCL] 데이터베이스 아키텍쳐 (0) | 2025.03.26 |
| KRX 데이터 경진대회 후기 (0) | 2025.03.06 |